about email inquiries
Unfortunately I had to abandon this a couple times over the past few months, so please stick to the following if you want me to answer your mail:
- Be polite. I'm done turning a blind eye to harsh tones for no reason.
- Have a quick browse on the website first to get an overview. A lot of things are already covered here. Yes, the docs are extensive, so no worries if you miss something in there, happy to point you to the right sub sections.
- Use English. If you don't speak english, use an online translator. Oh yes, I could do so as well, but it takes more of my time to do so all the time, than for you to do so just once.
- Please don't use AI to write your mail entirely. a) it's so obvious, so the exaggerated praises don't really mean anything to me and b) it's bloated for no reason, so mostly I have to wade through a wall of text to filter the tiny actual points.
--
daniel
xg data
no saudi pro league
v4 release
I decided to make some breaking changes and do a fresh v4 release and here we go. The main goals set for v4 were:
- flatten data structures
- improve consistency across resources
- improve expressiveness
- add control to response sizes by selectively unfolding specific nodes
- review/rewrite entire documentation
- remain as backward compatible as possible
Last but not least the API is more frontend-aware now, as I stumbled over several shortcomings while building native-stats.org on top of it, so I directly tackled them.
In the end I can say that I really like what I built, and I hope so do you.
--
daniel
World Cup 2022 - Qatar
https://api.football-data.org/v4/competitions/WC/matchesdaniel
Calculate homewin percentage
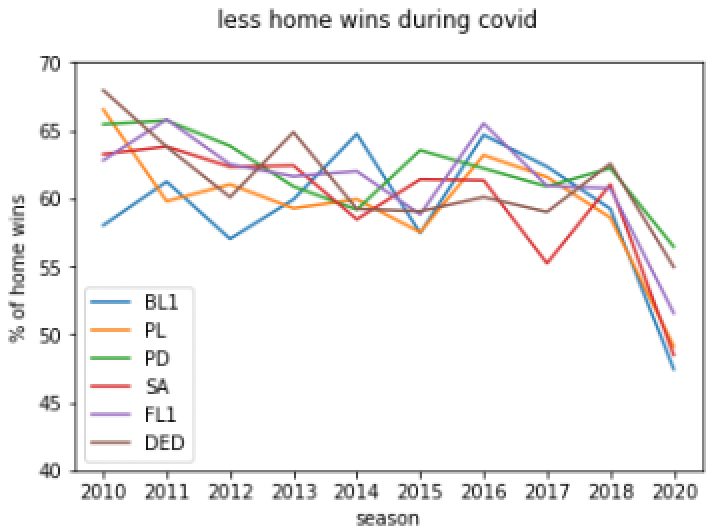
Use the python code below to create such linecharts by yourself:
#!/bin/python
import matplotlib
import matplotlib.pyplot as plt
import requests
import json
def get_home_wins_for_competition(competition_code):
base_uri = 'https://api.football-data.org/v2/competitions/' + competition_code + '/matches'
headers = { 'X-Auth-Token': 'YOUR_TOKEN_HERE', 'Accept-Encoding': '' }
retVal = []
seasons = [str(x) for x in range(2010,2020)]
for year in seasons:
uri = base_uri + "?season=" + str(year)
response = requests.get(uri, headers=headers)
matches = response.json()['matches']
home_wins = 0; match_counter = 0;
for m in matches:
if (m['score']['winner'] == "HOME_TEAM"):
home_wins += 1
if (m['score']['winner'] is not None and m['score']['winner'] != "DRAW"):
match_counter += 1
retVal.append(round((home_wins/match_counter)*100, 2))
return retVal
competitions = ['BL1', 'PL', 'PD', 'SA', 'FL1', 'DED']
seasons = [str(x) for x in range(2010,2020)]
values = {}
for key in competitions:
values[key] = get_home_wins_for_competition(key)
plt.xlabel('season')
plt.ylabel('% of home wins')
plt.ylim(40.0, 70.0)
for key in competitions:
plt.plot(seasons, values[key], label = key)
plt.legend()
plt.suptitle('less home wins during covid')
plt.show()
Added Odds to match resource
#!/bin/python
# @date 2020/02/25
# @author daniel (daniel@football-data.org)
import requests
import json
import time
uri = 'https://api.football-data.org/v2/matches'
headers = { 'X-Auth-Token': 'YOUR_KEY_HERE', 'Accept-Encoding': '' }
response = requests.get(uri, headers=headers)
upcoming_matches = response.json()['matches']
highest_odds = {"homeWin": 0.0, "draw": 0.0, "awayWin": 0.0}
matches = {"homeWin": None, "draw": None, "awayWin": None}
for m in upcoming_matches:
try:
if m['odds']['homeWin'] is not None and m['odds']['homeWin'] > highest_odds['homeWin']:
highest_odds['homeWin'] = m['odds']['homeWin']
matches['homeWin'] = m
if m['odds']['draw'] is not None and m['odds']['draw'] > highest_odds['draw']:
highest_odds['draw'] = m['odds']['draw']
matches['draw'] = m
if m['odds']['awayWin'] is not None and m['odds']['awayWin'] > highest_odds['awayWin']:
highest_odds['awayWin'] = m['odds']['awayWin']
matches['awayWin'] = m
except KeyError as e:
print('You need to enable Odds in User-Panel.')
print("Highest odds for upcoming games today for home win, draw and away win are as follows:\n")
print("homeWin: " + matches['homeWin']['homeTeam']['name'] + " against " + matches['homeWin']['awayTeam']['name'] + " (" + str(highest_odds['homeWin']) + ")")
print("draw: " + matches['draw']['homeTeam']['name'] + " against " + matches['draw']['awayTeam']['name'] + " (" + str(highest_odds['draw']) + ")")
print("awayWin: " + matches['awayWin']['homeTeam']['name'] + " against " + matches['awayWin']['awayTeam']['name'] + " (" + str(highest_odds['awayWin']) + ")")Best,
daniel
Simple calcs and happy new year!
Recently I watched a show on television where the guys talking tried to find reasons why there are so many goals in this years' season of the Bundesliga. I actually wasn't aware of that but these days I thought I'll prove that and see how easy/difficult that is by utilizing my own API.
Actually it was pretty straightforward using the python script below, which I don't want to hold back from you:
#!/bin/python
# Small python script to prove a TV hosts' statement of like
# 'Why is it, that this year there are loads of goals scored?'
#
# @date 2018/12/28
# @author daniel (daniel@football-data.org)
import requests
import json
for year in range(2018, 2016, -1):
uri = 'http://api.football-data.org/v2/competitions/BL1/matches?season=' + str(year)
headers = { 'X-Auth-Token': 'YOUR_TOKEN_HERE' }
response = requests.get(uri, headers=headers)
matches = response.json()['matches']
#finishedMatches = filter(lambda match: match['status'] == 'FINISHED', matches)
matchesUntilMatchdayX = filter(lambda match: match['matchday'] < 18, matches)
totalGoals = 0
for match in matchesUntilMatchdayX:
totalGoals += match['score']['fullTime']['homeTeam'] + match['score']['fullTime']['awayTeam']
print "Total goals scored in season " + str(year) + ": " + str(totalGoals)
print " That is an avg of " + str(round((float(totalGoals) / 18.0),2)) + " per matchday."
print " and an avg of " + str(round((float(totalGoals) / len(matchesUntilMatchdayX)),2)) + " per game."Don't forget to insert your own token and feel free to play around with it; e.g. use "PL" to see same statistics for the Premiere League or change the matchday in the lamba expression to see results for different sections of the season.
Best,
daniel
BTW: He was right :-)
Added limit filter to matches subresource
just a quick note: I added the limit filter to the team matches subresource, so if your programming language is lacking a head() or first() function on lists/collections, you can now easily get the latest match of your favourite team by firing:
http://api.football-data.org/v2/teams/67/matches?status=FINISHED&limit=1
http://api.football-data.org/v2/teams/67/matches?status=SCHEDULED&limit=1
Best,
daniel
Codes for Competitions back
I'm very happy to announce that I added values to the code-attribute of the competition resource back again (formerly known as leagueCodes).
They are back now and even more powerful as you can even use them now as identifier, e.g. by firing
https://api.football-data.org/v2/competitions/PL/matches
https://api.football-data.org/v2/matches?competitions=PL,BL1&status=FINISHED&dateFrom=2018-10-01&dateTo=2018-10-08
Additionally I added back the crestUrl attribute to the team (sub)resources and the standings. I also cumulated it to be named "crestUrl"; v1 was mixing this up over the different resources.
Best,
daniel
PHP-Lib updated
I finally updated the small PHP code that shows basic functions of the API. You can have a look at it here:
https://github.com/dfrt82/phplib-football-data
best,
daniel
On matches and status
with v2 matches have more fine grained status. See the status diagram below.
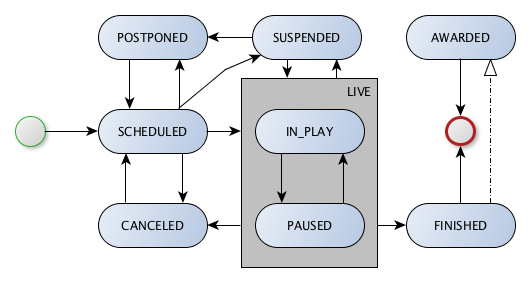
A match always starts with status "SCHEDULED". There is no TIMED status any more, so the regular workflow is a status change to IN_PLAY, to PAUSED, to IN_PLAY (again) and to FINISHED.
Take notice that there is a 'superior' status LIVE, that does not exist as a status per se, but you can use it in the matches resource as a filter. So you get all matches back that are currently IN_PLAY or PAUSED, thus LIVE :-)
AWARDED is also a new status as at times games find it's final result legally afterwards and mostly end 3 to 0 for one team then. Hope this is all clear and makes sense.
Best,
daniel
Finally - Football-Data API v2
Though Germany just got kicked out of the World Cup I'm very proud to announce, that v2 is finally online! It’s the biggest update of the API since I’ve started the project in 2014.
The top competitions will remain free in the new API. What was free in v1, remains free in v2 and will remain free forever!
The extra data/competitions are available under 3 new paid plans: Standard (25 competitions/€49 per month), Advanced (50 competitions/€99 per month) and Pro (144 competitions/€249 per month). These paid plans will help to support this project and fuel the development and growth of the football-data.org API.
What’s new in v2?- 144 competitions (leagues & cups) are now available through the API
- Live scores available for all matches
- Match fixtures are now updated every hour (instead of every day)
- League tables; Home/Away tables
- Match lineups and substitutes
- Goal scorers and assists
- Bookings (Yellow Cards, Red Cards)
- Team squads
There will be further updates in the upcoming days and weeks, so keep an eye on this blog to follow the latest changes.
If you have any questions, please contact me at daniel at football-data.org.
best,daniel
World Cup ahead
http://api.football-data.org/v1/competitions/467best, daniel
Major platform upgrade
Downtimes
things going on...
European Championships online.
PHP library
official release of v1 the 2015/12/03.
small update: API outage on 15th of august.
Small update
Almost the end of the season: further roadmap
Small udpate: direct date usage
New feature: realtime scores
new attribute: status on fixture resource.
why one should use football-data.org
alpha online.
alpha on track.
Major upgrades.
Small updates.
introducing the timeframe argument
small pragmatism change: pluralization
new resource: fixture
let the games begin.
content update for new seasons data.
Actually I'm doing an initial import of all the new seasons' data at the moment. You can expect all data to be complete to the end of july. As you can see, moreover I decided to add a small blog section to keep you posted about important changes, explain features, best practices, hints and so on. cheers
daniel.